Table of Contents
Introduction
In our ongoing effort to assess hardware performance for AI and machine learning workloads, today we’re publishing results from the built-in benchmark tool of llama.cpp, focusing on a variety NVIDIA GeForce GPUs, from the RTX 4090 down to the now-ancient (in tech terms) GTX 1080 Ti. Although this round of testing is limited to NVIDIA graphics cards, we plan to expand our scope in future benchmarks to include AMD offerings.
If you’re interested in how NVIDIA’s professional GPUs performed using this benchmark, then follow this link to check out those results.

Image
Test Setup
Test Platform
| CPU: AMD Ryzen Threadripper PRO 7985WX 64-Core |
| CPU Cooler: Asetek 836S-M1A 360mm Threadripper CPU Cooler |
| Motherboard: ASUS Pro WS WRX90E-SAGE SE BIOS Version: 0404 |
| RAM: 8x Kingston DDR5-5600 ECC Reg. 1R 16GB (128GB total) |
| GPUs: NVIDIA GeForce RTX 4090 24GB NVIDIA GeForce RTX 4080 SUPER 16GB NVIDIA GeForce RTX 4080 16GB NVIDIA GeForce RTX 4070 Ti SUPER 16GB NVIDIA GeForce RTX 4070 Ti 12GB NVIDIA GeForce RTX 4070 SUPER 12GB NVIDIA GeForce RTX 4070 12GB NVIDIA GeForce RTX 4060 Ti 8GB NVIDIA GeForce RTX 4060 8GB NVIDIA GeForce RTX 3080 Ti 12GB NVIDIA GeForce RTX 2080 Ti 11GB NVIDIA GeForce GTX 1080 Ti 11GB Driver Version: 560.70 |
| PSU: Super Flower LEADEX Platinum 1600W |
| Storage: Samsung 980 Pro 2TB |
| OS: Windows 11 Pro 23H2 Build 22631.3880 |
Llama.cpp build 3140 was utilized for these tests, using CUDA version 12.2.0, and Microsoft’s Phi-3-mini-4k-instruct model in 4-bit GGUF. Both the prompt processing and token generation tests were performed using the default values of 512 tokens and 128 tokens respectively with 25 repetitions apiece, and the results averaged.
GPU Performance
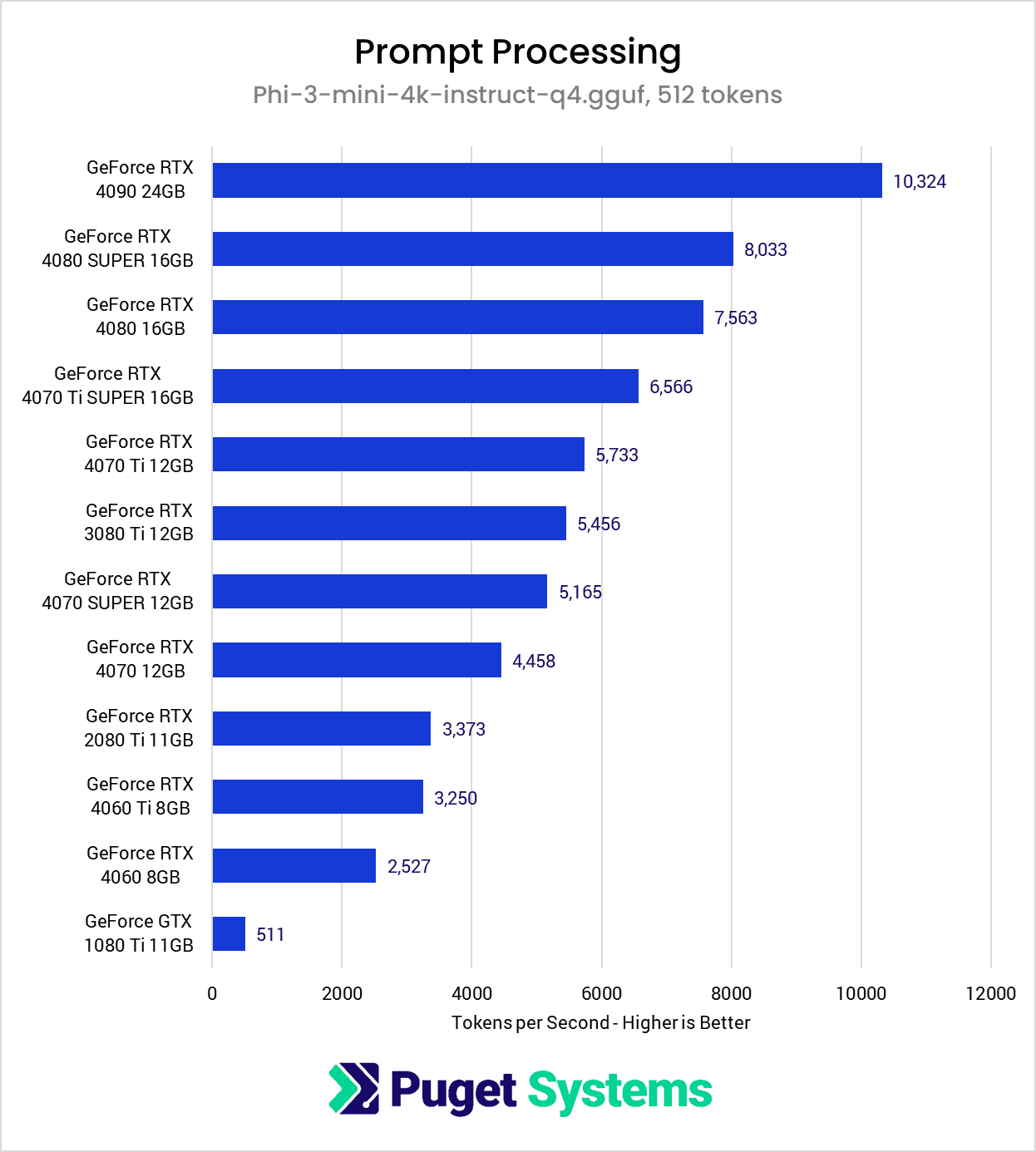
Image
Within the latest GeForce RTX 4000 series, the rankings of the cards in the prompt processing test are as we would expect based on the models’ positioning within their product stack. We found that the RTX 4090 was 28.5% faster than the RTX 4080 SUPER, which was only 6.2% faster than the standard RTX 4080. Especially with it’s hefty 24GB of VRAM, the RTX 4090 continues to be a great choice for LLMs, but the RTX 4080 SUPER is also likely worth considering since it actually has a lower MSRP than the RTX 4080. Although, at the 16GB mark, the RTX 4070 Ti SUPER is a worthwhile contender to the RTX 4080 SUPER, with an overall lower cost, but similar price/performance ratio. This all assumes, however, that prompt processing performance is your main concern over token generation, which is unlikely scenario in many workflows.
Interestingly, we find that last-generation’s 3080 Ti came out ahead of the RTX 4070 SUPER and RTX 4070, and the venerable RTX 2080 Ti managed to edge out the RTX 4060 Ti variant. Finally, with its complete lack of tensor cores, the GTX 1080 Ti truly shows its age, scoring five times slower than its closest competition, the RTX 4060.
When we compare these results with the technical specifications of these GPUs, then it becomes clear that FP16 performance has a direct impact on how quickly they are able process prompts in the llama.cpp benchmark. FP16 performance is almost exclusively a function of both the number of tensor cores and which generation of tensor core the GPUs were manufactured with. This explains why, with it’s complete lack of tensor cores, the GTX 1080 Ti’s FP16 performance is anemic compared to the rest of the GPUs tested. However, the fact that the RTX 3080 Ti was able to come out ahead against the RTX 4070 SUPER indicates that FP16 performance is not the only factor in effect during prompt processing, and the following section should shine some light on what else we should be considering.
| GPU | FP16 (TFLOPS) | Tensor Core Count | Tensor Core Generation |
|---|---|---|---|
| RTX 4090 | 82.58 | 512 | 4th |
| RTX 4080 SUPER | 52.22 | 320 | 4th |
| RTX 4080 | 48.74 | 304 | 4th |
| RTX 4070 Ti SUPER | 44.10 | 264 | 4th |
| RTX 4070 Ti | 40.09 | 240 | 4th |
| RTX 3080 Ti | 34.10 | 320 | 3rd |
| RTX 4070 SUPER | 35.48 | 224 | 4th |
| RTX 4070 | 29.15 | 184 | 4th |
| RTX 2080 Ti | 26.90 | 544 | 2nd |
| RTX 4060 Ti | 22.06 | 136 | 4th |
| RTX 4060 | 15.11 | 96 | 4th |
| GTX 1080 Ti | .18 | 0 | N/A |
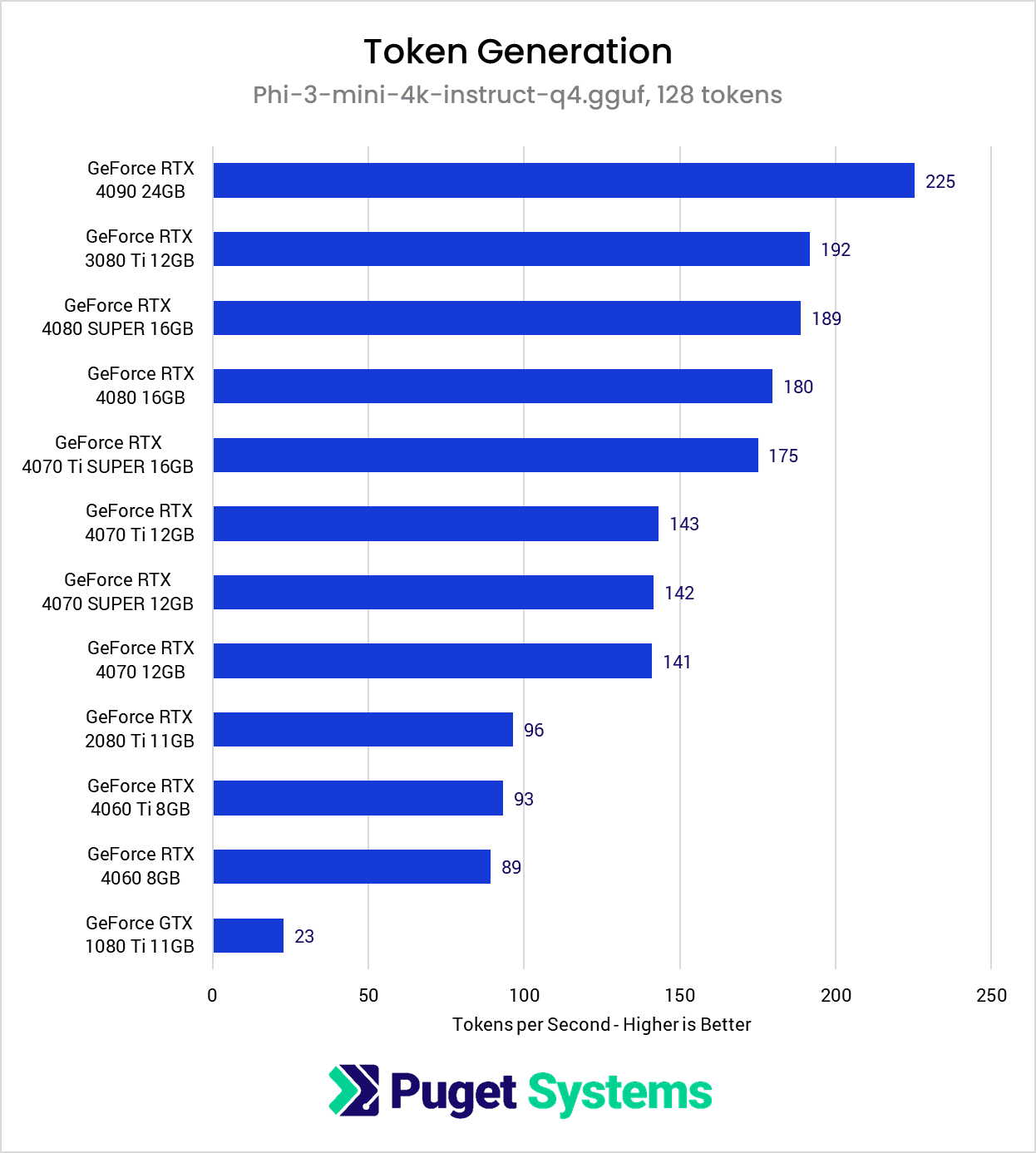
Image
Once again, the RTX 4090 continues to show its dominance by landing at the top of the token generation chart, but surprisingly, the RTX 3080 Ti took second place, jumping up four positions compared to the prompt processing results, with a score functionally equivalent to the much newer RTX 4080 SUPER.
Again, if we refer back to the technical specifications of these GPUs, we can see how the older RTX 3080 Ti was able to achieve this result: through its notable memory bandwidth. Although the two RTX 4080 variants have considerably more FP16 compute capability compared to the RTX 3080 Ti (~50TFLOPS vs. ~35 TFLOPS), the roughly 25% more memory bandwidth on the RTX 3080 Ti allows it to come out just ahead of the newer GPUs during token generation.
Compared to the prompt processing results, we also see that the token generation test narrowed the performance gap between certain models. For example, in prompt processing, the percentage increase from an RTX 4070 Ti SUPER to the RTX 4080 SUPER was about 22%, but during token generation, the increase was only 8%. Likewise the percentage increase from an RTX 4070 to an RTX 4070 Ti shrinks from 25% during prompt processing, to the two cards achieving nearly identical token generation scores.
But similar to the prompt processing results, if we look at where older cards like the RTX 2080 Ti and GTX 1080 Ti land on the chart, we can see that memory bandwidth is not the end-all-be-all specification for token generation, and FP16 compute performance still has a role to play. Otherwise, we’d expect to see the GTX 1080 Ti achieve a better result, considering its memory bandwidth is comparable to the RTX 4070 and its variants.
One somewhat anomalous result is the unexpectedly low tokens per second that the RTX 2080 Ti was able to achieve. The RTX 2080 Ti has more memory bandwidth and FP16 performance compared to the RTX 4060 series GPUs, but achieves similar results. We expect this to be a result of either software optimizations for the newer generations of GPUs or increased overhead from using a higher number of less capable tensor cores (544 second gen cores vs. 96-136 fourth gen cores).
| GPU | Memory Bandwidth (GB/s) |
|---|---|
| RTX 4090 | 1008.4 |
| RTX 3080 Ti | 912.4 |
| RTX 4080 SUPER | 736.3 |
| RTX 4080 | 716.8 |
| RTX 4070 Ti SUPER | 672.3 |
| RTX 4070 Ti | 504.2 |
| RTX 4070 SUPER | 504.2 |
| RTX 4070 | 504.2 |
| RTX 2080 Ti | 616 |
| RTX 4060 Ti | 288 |
| RTX 4060 | 272 |
| GTX 1080 Ti | 484.4 |


Final Thoughts
These results emphasize an important consideration when choosing GPUs for LLM usage: while raw memory capacity is very important, it is not the only factor that should be taken into account. It’s also important to consider the memory bandwidth and overall compute performance of a GPU in order to get a comprehensive understanding of a GPU’s suitability for LLMs.
This is just the starting point for our LLM testing series. Future updates will include more topics, such as inference with larger models, multi-GPU configurations, testing with AMD & Intel GPUs, and model training as well. We’re eager to hear from you – if there’s a specific aspect of LLM performance you’d like us to investigate, please let us know in the comments!
Looking for an AI and Scientific Computing workstation?
We build computers tailor-made for your workflow.
Don’t know where to start?
We can help!
Get in touch with one of our technical consultants today.