How do a selection of GPUs from NVIDIA’s professional lineup compare to each other in the llama.cpp benchmark?

How do a selection of GPUs from NVIDIA’s professional lineup compare to each other in the llama.cpp benchmark?

How do a selection of GPUs from NVIDIA’s GeForce series compare to each other in the llama.cpp benchmark?

What considerations need to be made when starting off running LLMs locally?

What effect, if any, does a system’s CPU speed have on GPU inference with CUDA in llama.cpp?
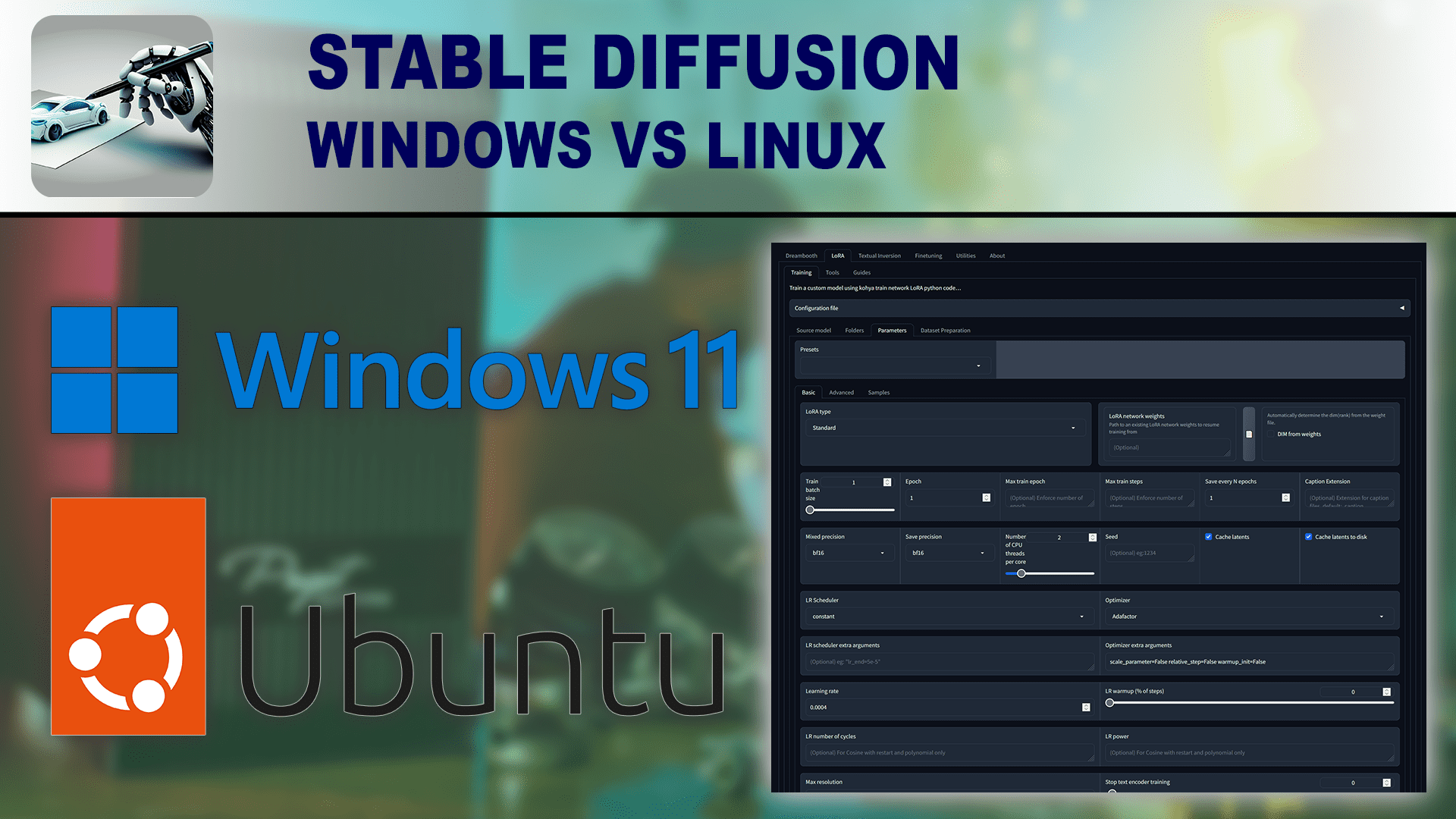
How does the choice of Operating System affect image generation performance in Stable Diffusion?

With 2023 at a close, we wanted to look back at the sales trends we saw for CPU, GPU, storage, and OS.

How does performance compare across a variety of consumer-grade GPUs in regard to SDXL LoRA training?

How does performance compare across a variety of professional-grade GPUs in regard to SDXL LoRA training?
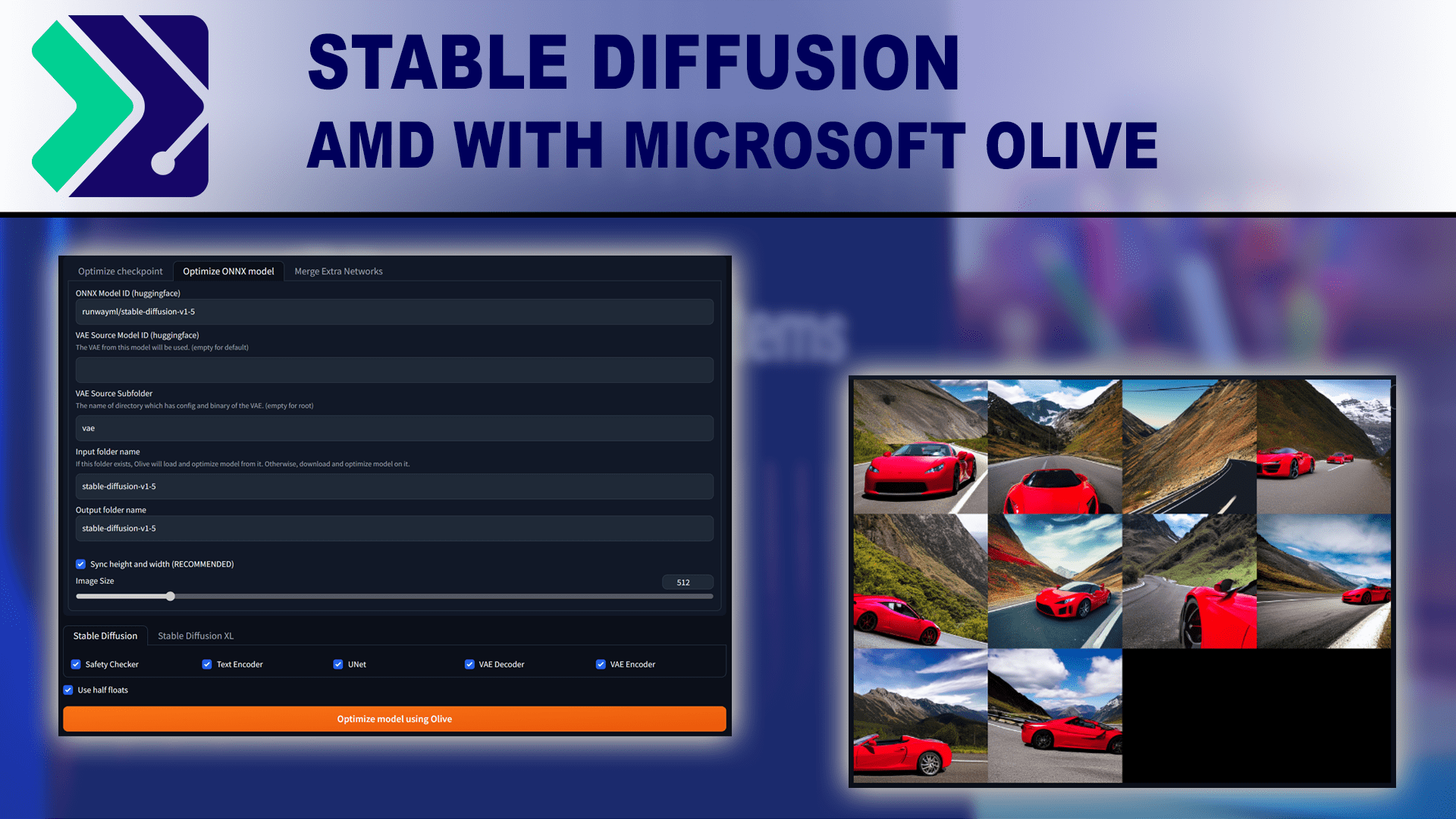
AMD has published a guide outlining how to use Microsoft Olive for Stable Diffusion to get up to a 9.9x improvement in performance. But is that enough to catch up to NVIDIA?
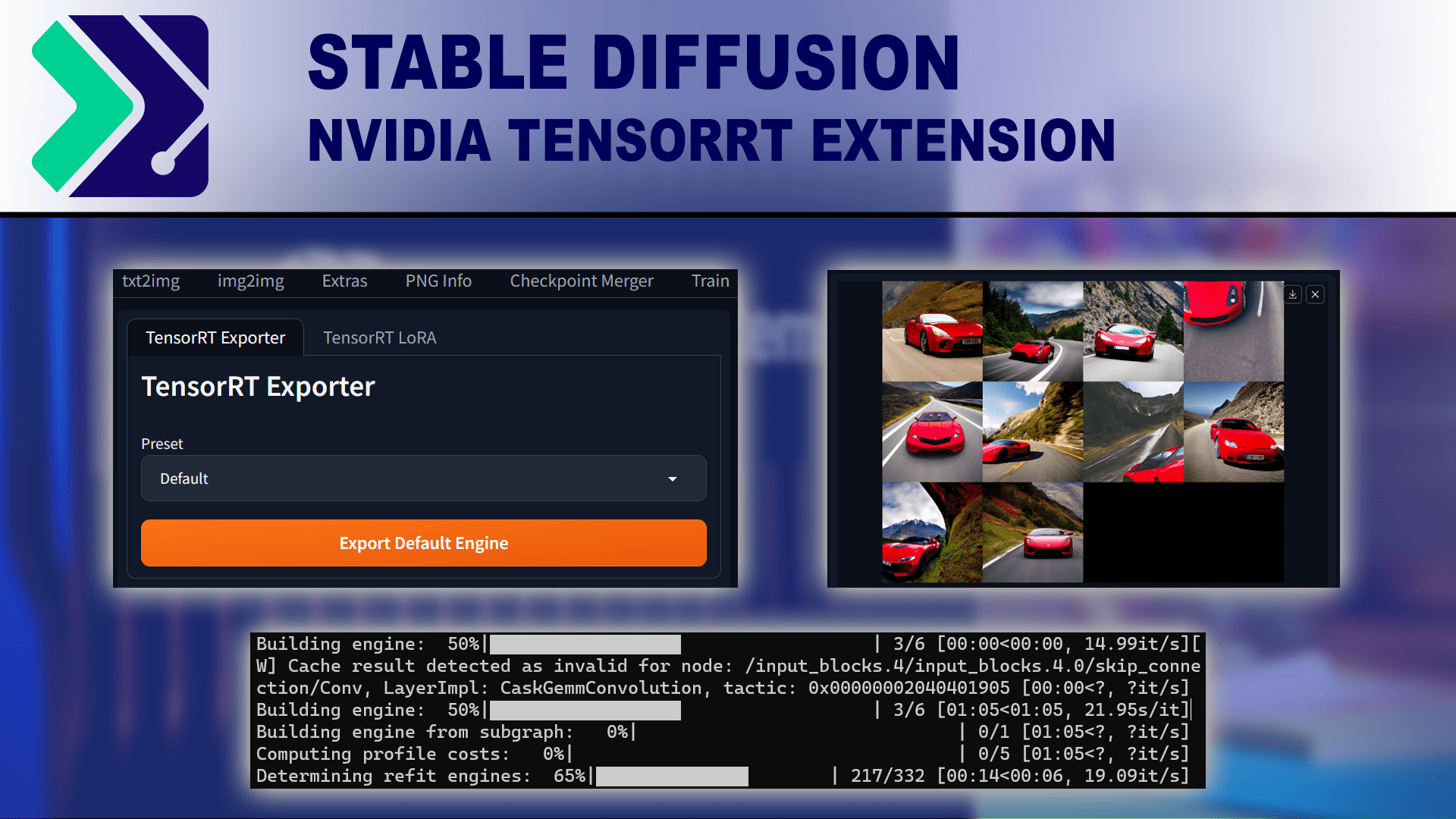
NVIDIA has released a TensorRT extension for Stable Diffusion using Automatic 1111, promising significant performance gains. But does it work as advertised?
Puget Systems builds custom workstations, servers and storage solutions tailored for your work.
We provide:
Extensive performance testing
making you more productive and giving better value for your money
Reliable computers
with fewer crashes means more time working & less time waiting
Support that understands
your complex workflows and can get you back up & running ASAP
A proven track record
as shown by our case studies and customer testimonials
