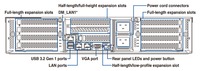
Quad GPU Large Language Model Server
Compact 2U rackmount server supporting up to four NVIDIA GPUs for fine-tuning and inference with AI large language models.
Overview
Quad GPU 2U server supporting NVIDIA RTX Ada and L40S graphics cards
- Up to 192GB of VRAM across four GPUs
- Great for 70B parameter fp16 inference and fine-tuning smaller models
- Requires two power connections on separate circuits
- 240V power required for PSU redundancy
Not sure what you need?
Tell us your situation and one of our experts will reply within 1 business day to help configure the right computer for your workflow. If you don’t see what you are looking for here, check out our other systems for more options.