Table of Contents
Introduction
From cost, data privacy, or a desire to have more choice and control over the model being run, there are a number of reasons why someone might choose to run an LLM locally, rather than using a service such as Microsoft Co-Pilot or ChatGPT. However, doing so can be overwhelming if you have not done it before; because of how rapidly the technology is changing, a lot of information you may find on the internet can be outdated.
This article is intended as an introductory guide for those interested in running their own LLM. It isn’t intended to be comprehensive or delve into the deeper aspects of LLMs, but to provide insight into some of the variables to consider when taking the first steps.

Image
Hardware Considerations for Running a Local LLM
It is perhaps obvious, but one of the first things to think about when considering running local LLMs is the hardware that you have available to utilize. Although it’s true that LLMs can be run on just about any computer, it’s also true that in order to get the best performance, the system should have one or more graphics cards that can be utilized for the LLM workload.
If you are doing your first exploration of running a local LLM, you will likely use what you already have available. However, there are certain hardware options that will make your life easier, either due to capability or performance.
Consumer vs Workstation Platform
The choice of platform typically doesn’t directly impact performance, but rather, impacts the options available when planning a build. For example, the number and layout of PCIe lanes will affect how many GPUs can be effectively utilized within a system, and for CPU inference, the number of memory channels is an important consideration as well (more details in the RAM & Storage section below).
For both PCIe lanes and memory channels, workstation platforms like AMD Threadripper Pro and Intel Xeon W can provide significantly more capability than a consumer platform like AMD Ryzen or Intel Core. That might not be important when you are first starting out and working with smaller models, but as you progress to larger models and multi-GPU configurations, the benefits of a workstation platform will only grow.
Between AMD and Intel platforms, an Intel platform running an LLM with a given GPU is going to perform nearly identical to an AMD platform also running an LLM with that same GPU.
Using CPU vs. GPU for Inference
One of the first forks in the road that you will encounter when starting with an LLM is whether to perform inference using the CPU or GPU. If you have a workstation with a graphics card released in the past five years or so, then it’s practically guaranteed that performing inference with your GPU will provide much better performance than if you were to use the CPU. However, especially with single-GPU configurations, the amount of VRAM that the GPU features (typically anywhere from 8GB to 48GB) is going to be the limiting factor with regard to which models that can be run via the GPU.
In contrast, CPU inference uses the system RAM instead of the VRAM, making it much easier to run larger models that may not otherwise be able to be loaded into a system’s VRAM. The major downside of this approach is that performance is going to be much lower, somewhere in the range of 10x to 100x slower, compared to running the same model on a capable GPU.
In addition to strictly CPU or GPU approaches, there are inference libraries that support a hybrid method of inference utilizing both CPU/RAM and GPU/VRAM resources, most notably llama.cpp. This can be a good option for those who want to run a model that cannot fit entirely within their VRAM. Intuitively, this results in performance that lands somewhere between pure CPU and pure GPU inference. In this mode, the more of a model that has to be offloaded into system RAM, the greater the performance impact.
NVIDIA vs AMD GPU Performance & Capability
In the LLM space, the easy answer to the NVIDIA vs. AMD question is: NVIDIA. The primary reason is the broad support for CUDA across both Linux and Windows in a variety of inference libraries. Many projects, especially within Windows, are built for and expect to run on NVIDIA cards. In addition to the wide software support base, NVIDIA GPUs also have an advantage in terms of raw performance.
But this doesn’t mean that AMD should be written off entirely, especially for anyone interested in trying local LLMs on AMD GPUs that they already own. There aren’t many options within Windows, but one example is LM Studio, which offers a technical preview with ROCm support. If your system is running Linux with an AMD GPU, then you have many more options because of the improved ROCm support under Linux.


RAM & Storage Considerations
Except in the case of CPU inference, RAM is a secondary concern at most. During GPU inference, RAM’s primary use is to facilitate loading a model’s weights from storage into VRAM. For this reason, we recommend having at least as much RAM as VRAM in a system, but preferably 1.5-2x more RAM than VRAM. Attempting to load a model without sufficient RAM can fail if the capacity of the RAM + system page file is exceeded by the model, even if that model can fit on the available VRAM. However, once the model is loaded, then the RAM’s job is essentially done.
The biggest factor limiting performance during CPU inference is RAM memory bandwidth, and maximizing bandwidth directly leads to performance. This means that faster memory clock speed is preferred over lower latency, and platforms that support more memory channels, such as AMD Threadripper PRO or EPYCs, are better suited for CPU inference.
Regardless of the inference method, storage does not play a significant role. Like RAM in the case of GPU inference, once a model is loaded, then there’s not much for the storage to do. A drive’s read performance does impact how quickly a model can be read and loaded into memory, so utilizing a fast NVMe drive to hold models’ weights will help minimize the time spent loading into RAM or VRAM. But unless someone is frequently loading and testing a variety of different models, then this isn’t likely to be much of a concern.
However, if testing a variety of models is in your future, then it’s worth keeping in mind that with some models measuring in the hundreds of GB, drive space can quickly become limited with even a modest library of larger models.
Software / OS Options for Local LLM
Overall, Linux is the OS of choice for running LLMs for a number of reasons. Most AI/ML projects are developed on Linux and are assumed to be run on Linux as well. Even when a project does support Windows, it’s reasonable to assume that support and documentation on the Windows version are not a priority compared to the native Linux version. Linux can also be expected to use fewer system resources, and in particular, desktop VRAM usage is reliably lessened compared to Windows. This could make the difference between successfully loading a model and failing with an out of memory error when working with constrained a VRAM budget. Finally, Windows lacks proper NCCL support, which prevents many of the optimizations available for multi-GPU computation, so Linux is the OS of choice for multi-GPU configurations.
All of that said, it’s never been easier to get started with LLMs, regardless of your OS of choice. Tools like Chat with RTX and LM Studio provide simple GUIs that allow just about anyone to start generating text without ever touching a command line or virtual environment. Going a step further, text-generation-webui (commonly referred to by the author’s name, oobabooga) offers a variety of libraries for running models with either GPU or CPU inference. In addition to its flexibility, text-generation-webui can be easily installed on Linux or Windows with the included installation scripts, and can be a great stepping stone for those looking to explore more robust and customizable LLM libraries & projects.
Multi-User access
Although this article is primarily focused on running LLMs on local hardware for the benefit of a single user, we want to briefly touch on some topics to think about when planning to allow other users to access and utilize an LLM server. Although there are some hardware considerations to make with regard to multi-user support, especially if you are planning on serving hundreds or thousands of users, much of the planning lies on the software side. One example of this is a feature known as “batching”. There are multiple batching methods, but they all allow multiple inputs to an LLM to be processed in parallel, which greatly improves throughput, but with the downside of increased memory usage. Serially processing inputs isn’t usually much of a concern for a single user, but if you are providing access to your LLM to others, you’ll want to make sure that the LLM software backend supports batching.
Even if you don’t plan on giving access to other users, it’s often the case that you won’t be interfacing directly with the LLM, but will instead be accessing it via an API. This can be accomplished by submitting commands to the API server directly via the terminal, or perhaps more commonly, via an application connected to the server. Considering the growing number of LLM applications and plugins that function in this manner, such as Dot or OpenAI Sublime Text Plugin, (and many more including Android and iOS apps), hosting and accessing a local LLM in this manner provides incredible flexibility. Some backends, such as Ollama or vLLM are strictly designed for this use-case, but others, like text-generation-webui support this functionality when run with a command line argument (–api). Just be sure that you don’t inadvertently expose your server to unauthorized users!
Which LLM to use
The two big questions to ask yourself when choosing which model to run are:
1. Does it do what I want it to do?
2. Does it fit within the available system resources?
The first question is relatively simple to answer. For example, if you want a model that can be used to translate Japanese, then your best option is to find a model that was trained on Japanese text. So instead of choosing Meta-Llama-3.1-8B-Instruct, which supports English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai, you’ll probably be better served by choosing Qwen2-7B-Instruct, which was trained on 29 languages, including English and Japanese.
Similarly, if you want a model to help you with coding, then find a coding-specific model or a more general model that had code included in its training data, if you want a model that can describe the contents of images, then you’ll need a multimodal model that can accept both text and images as inputs, like idefics2-8b-base. However, it’s also the case that one of the most interesting and powerful features of these models is their ability to “generalize”, meaning that they are often able to solve problems despite not being explicitly trained with data related to those problems. Especially as models become more sophisticated over time, you may find that a newer, generalized model outperforms an older, more specialized model – even on tasks that the specialized model was trained for!
The question of system resources is also relatively straightforward, but like many aspects of the AI/ML world, increases in complexity as we dig deeper. The main point is determining whether the system has enough VRAM (GPU inference) or RAM (CPU inference) to load the model into memory for inference. The biggest factor that affects the size of the model is the parameter count, which is typically counted in the billions of parameters for current-day LLMs. It’s fairly standard practice to list parameter counts within the name of the model, letting us quickly gauge the approximate size of a model at a glance. As an example, Meta’s recently released Llama 3.1 series of models come in three sizes, 8B, 70B, and 405B.
Models are generally released in FP16 or BF16 precision, which for the purposes of estimating the size of a given model, gives us an easy calculation: multiply the parameter count (in billions) by two to get the amount of gigabytes of memory the model will require. That means that an 8B parameter model will need roughly 16GB of memory, while Meta’s new 405B parameter model requires a whopping 810 GB of memory!
However, this is only true when the model is being run in FP16/BF16 precision. The process of “quantizing” a model is a method that is used to reduce a model’s memory footprint at the cost of accuracy and can be thought of as “compressing” the model to fit onto hardware which might otherwise not be sufficient to run the model at its native precision. Therefore, with a quantized model, simply multiplying the parameter count will not give us an accurate estimate of the memory requirements.
Another method for estimating a model’s requirements, quantized or not, is to simply review the file size of the weights (usually a series of .safetensors files). The total file size should more or less be about equal to how much memory the model will require. Quantized models are generally distinguished from the original version by the inclusion of an acronym denoting the quantization method, such as GPTQ, GGUF, AWQ, exl2, and others.
While the parameter count of a model is usually the most significant variable affecting a model’s memory footprint, it’s also important to consider the context window, which is essentially how much working memory a model has or how much it can “remember” at any given time, measured in tokens. Just in the past year, we’ve seen tremendous improvements in context sizes for open models. To use Meta’s Llama series as an example, Llama 1 debuted with a maximum of 2048 tokens of context, then Llama 2 with 4096 tokens, Llama 3 with 8192 tokens, and now Llama 3.1 with 128K tokens. However, context doesn’t come for free, and other than performance concerns outside of the breadth of this topic, the main issue is that it requires memory. This means that in addition to the model’s weights, additional memory needs to be provisioned for the context, and the larger the context window of the model, the more memory it will require.
The charts below demonstrate how widely VRAM usage can vary for a given model, in this case, Meta-Llama-3.1-8B-Instruct, depending on the precision used, the size of the context window, and other optimization options.





Using the method of multiplying the parameter count (in billions) of a BF16/FP16 model by two with Llama 3.1 8B gives us an estimate of 16GB of VRAM. In practice, we see that when loading Llama 3.1 8B in its native precision of BF16 using the transformers library, we find that the model itself consumes just over 15 GB of VRAM (Chart #1), so the quick “napkin math” estimate is pretty close. Additionally, once the model is downloaded, we can confirm the reported size on disk correlates quite closely as well: Ubuntu reports 16.1 GB of disk space and Windows reports 14.9GB.
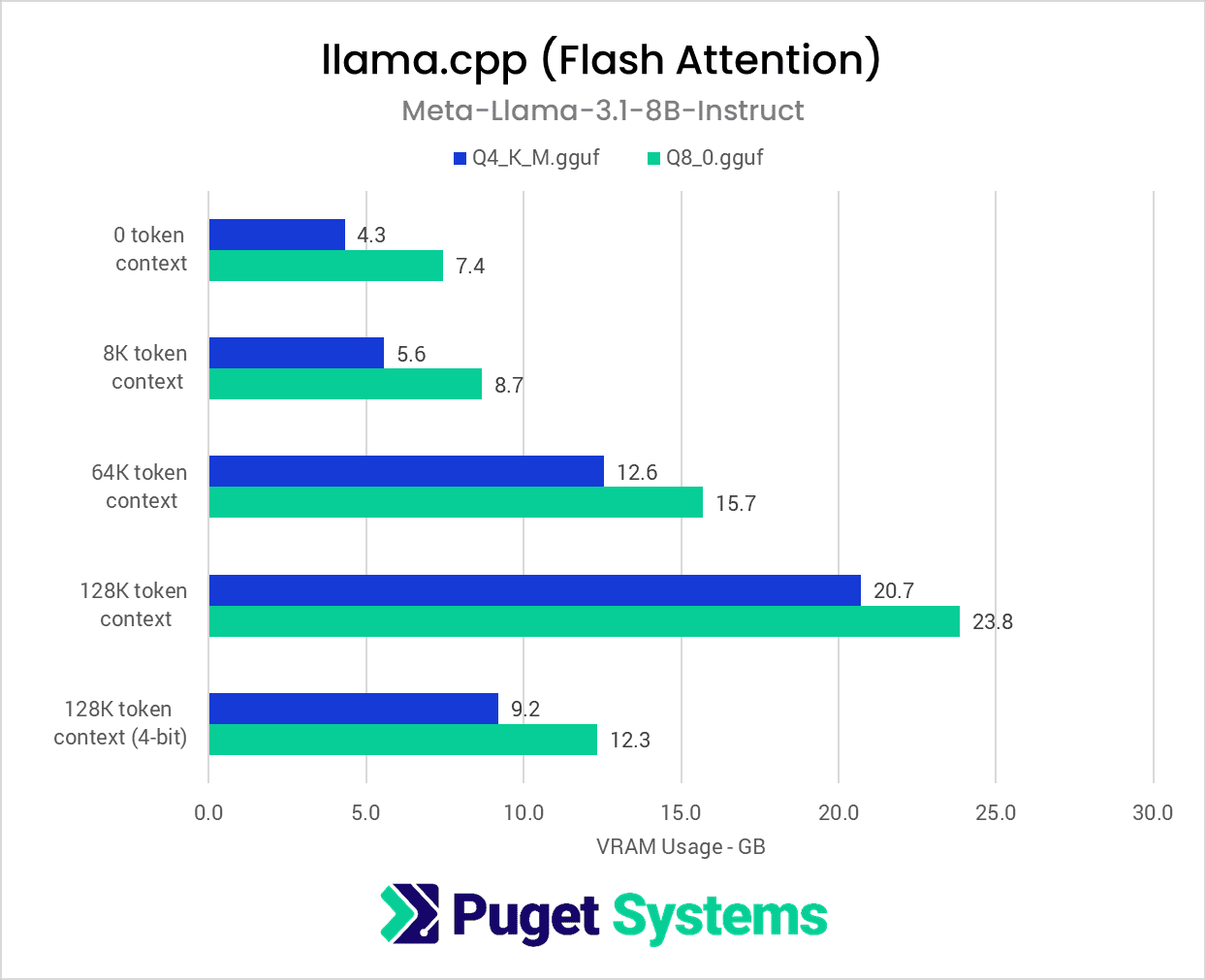
We also tested 4-bit and 8-bit quantized versions of the same model using the llama.cpp library (Chart #2). Intuitively, we find that compared to the BF16 version, the 8-bit quantization requires about half as much VRAM, and the 4-bit quantization requires about one fourth as much. Two rounds of llama.cpp testing was performed, with and without Flash Attention. We see that Flash Attention (Chart #3) reduces the memory impact of the context window, with its effects more pronounced the more context there is. On top of that, the context can be quantized to 4-bit from FP16, further reducing the toll that a large context has on memory. Together, both of these optimizations reduce the VRAM load to just 9.2GB compared 28.6GB with these options disabled.
All told, this means total VRAM usage estimates quickly become complicated once the context window is factored in, especially when also considering very large context windows and techniques such as Flash Attention or context quantization. However, knowing that we need to account for the context window is half the battle, and planning for an additional 15% of memory on top of the model itself will generally provide enough room for context for usability.
One last consideration when choosing a model is that it can be worth reviewing LLM leaderboards to get a general idea of how different models compare against each other. While there’s no perfect benchmark and concerns exist regarding models being trained on benchmark data to inflate their scores, they can certainly help paint a picture of the relative capabilities of the benchmarked models. The LMSys Leaderboard is one example, and it includes scores for proprietary models such as ChatGPT. Alternatively, the Open LLM Leaderboard is restricted to models that are free to download and run by anyone.
Final Thoughts
As we mentioned earlier in the article, it’s never been easier to start running LLMs on local hardware. Although we can’t possibly cover all of the variables to consider in this space within a single post, we hope that this article has given you the tools necessary to take the first steps to explore this exciting frontier of computing.
We plan to cover more in-depth topics in the future, such as how to configure and benchmark an LLM server for multiple users, comparing consumer and pro GPUs for LLM usage, and more. And if there are any topics you would like us to prioritize, please let us know in the comments!
Looking for an AI and Scientific Computing workstation?
We build computers tailor-made for your workflow.
Don’t know where to start?
We can help!
Get in touch with one of our technical consultants today.