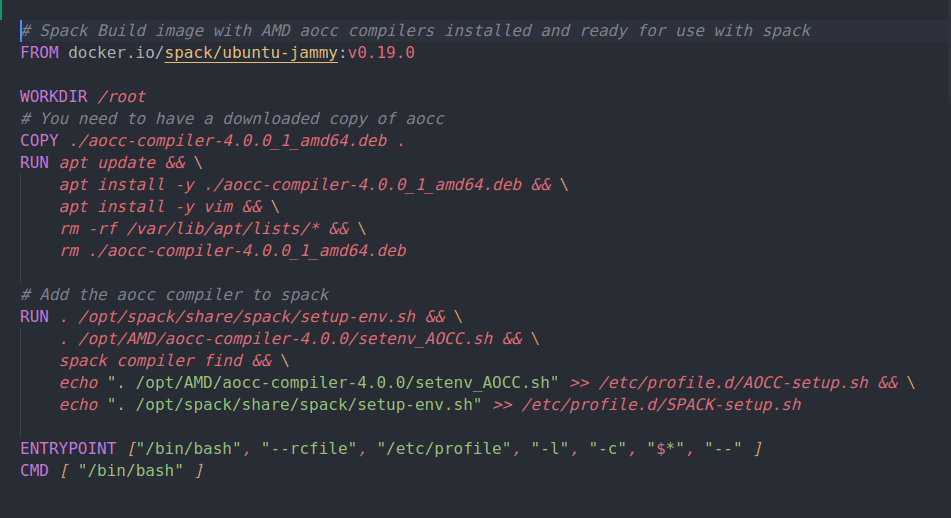
AMD has recently released version 4.0 of their AOCC compiler which includes support for AVX512 on the Zen4 architecture. This post details building a Docker image containing the Spack package manager/build system together with AMD AOCCv4.0.0 compilers. This will be used as the build image for multi-stage Dockerfiles that will be used to compile scientific applications and benchmarks with targeted Zen3/4 optimizations. It is the first step in that process.